Kubernetes 节点
节点作用
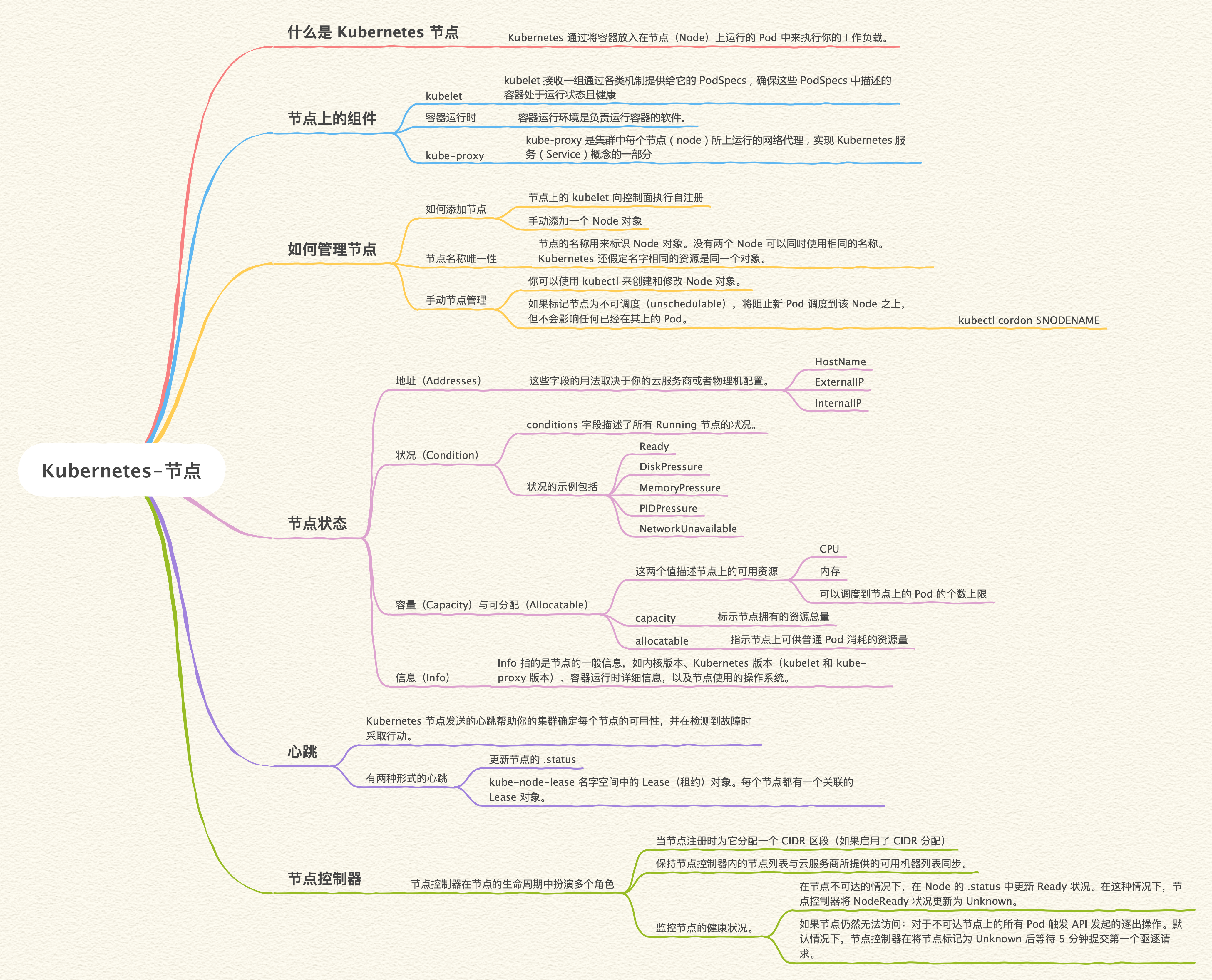
Kubernetes 通过将容器放入在节点(Node)上运行的 Pod 中来执行你的工作负载。
节点可以是一个虚拟机或者物理机器,取决于所在的集群配置。
每个节点包含运行 Pod 所需的服务,这些节点由控制平面(Control Plane)负责管理。
节点上的组件
节点上的组件包括:
- kubelet:一个在集群中每个节点上运行的代理。它保证容器都运行在 Pod 中。
- 容器运行时:容器运行时是负责运行容器的软件。
- kube-proxy:kube-proxy 是集群中每个节点(node)所上运行的网络代理,是实现 Kubernetes 服务(Service)概念的一部分。
如何管理节点
如何添加节点
向 API 服务器添加节点的方式主要有两种:
- 节点上的 kubelet 向控制面执行自注册
- 手动添加一个 Node 对象
节点名称唯一性
节点的名称用来标识 Node 对象。没有两个 Node 可以同时使用相同的名称。Kubernetes 还假定名字相同的资源是同一个对象。
节点状态
一个节点的状态包含以下信息:
- 地址(Addresses)
- 状况(Condition)
- 容量与可分配(Capacity)
- 信息(Info)
地址
以下这些字段的用法取决于你的云服务商或者物理机配置。
- HostName:由节点的内核报告。可以通过 kubelet 的 –hostname-override 参数覆盖。
- ExternalIP:通常是节点的可外部路由(从集群外可访问)的 IP 地址。
- InternalIP:通常是节点的仅可在集群内部路由的 IP 地址。
状况
conditions 字段描述了所有 Running 节点的状况。状况的示例包括:
| 节点状况 | 描述 |
|---|---|
| Ready | 如节点是健康的并已经准备好接收 Pod 则为 True;False 表示节点不健康而且不能接收 Pod;Unknown 表示节点控制器在最近 node-monitor-grace-period 期间(默认 40 秒)没有收到节点的消息 |
| DiskPressure | True 表示节点存在磁盘空间压力,即磁盘可用量低, 否则为 False |
| MemoryPressure | True 表示节点存在内存压力,即节点内存可用量低,否则为 False |
| PIDPressure | True 表示节点存在进程压力,即节点上进程过多;否则为 False |
| NetworkUnavailable | True 表示节点网络配置不正确;否则为 False |
容量(Capacity)与可分配(Allocatable)
这两个值描述节点上的可用资源:
- CPU
- 内存
- 可以调度到节点上的 Pod 的个数上限
capacity 块中的字段标示节点拥有的资源总量。allocatable 块指示节点上可供普通 Pod 消耗的资源量。
信息(Info)
Info 指的是节点的一般信息:
- 内核版本
- Kubernetes 版本(kubelet 和 kube-proxy 版本)
- 容器运行时详细信息
- 节点使用的操作系统
kubelet 从节点收集这些信息并将其发布到 Kubernetes API。
心跳
Kubernetes 节点发送的心跳帮助你的集群确定每个节点的可用性,并在检测到故障时采取行动。
对于节点,有两种形式的心跳:
- 更新节点的 .status
- kube-node-lease 名字空间中的 Lease(租约)对象。每个节点都有一个关联的 Lease 对象。
与 Node 的 .status 更新相比,Lease 是一种轻量级资源。使用 Lease 来表达心跳在大型集群中可以减少这些更新对性能的影响。
kubelet 负责创建和更新节点的 .status,以及更新它们对应的 Lease。
- 当节点状态发生变化时,或者在配置的时间间隔内没有更新事件时,kubelet 会更新 .status。.status 更新的默认间隔为 5 分钟(比节点不可达事件的 40 秒默认超时时间长很多)。
- kubelet 会创建并每 10 秒(默认更新间隔时间)更新 Lease 对象。Lease 的更新独立于 Node 的 .status 更新而发生。如果 Lease 的更新操作失败,kubelet 会采用指数回退机制,从 200 毫秒开始重试,最长重试间隔为 7 秒钟。
节点控制器
节点控制器在节点的生命周期中扮演多个角色:
- 当节点注册时为它分配一个 CIDR 区段(如果启用了 CIDR 分配)
- 保持节点控制器内的节点列表与云服务商所提供的可用机器列表同步。如果在云环境下运行,只要某节点不健康,节点控制器就会询问云服务是否节点的虚拟机仍可用。如果不可用,节点控制器会将该节点从它的节点列表删除。
- 监控节点的健康状况。节点控制器负责:
- 在节点不可达的情况下,在 Node 的 .status 中更新 Ready 状况。在这种情况下,节点控制器将 NodeReady 状况更新为 Unknown。
- 如果节点仍然无法访问:对于不可达节点上的所有 Pod 触发 API 发起的逐出操作。默认情况下,节点控制器在将节点标记为 Unknown 后等待 5 分钟提交第一个驱逐请求。
参考资料
思维导图